graph = dict() cfg = idaapi.FlowChart(function) exclusive_nodes = list() target_length = 65 first = None end = 9177 jmp_dict = dict() for block in cfg: graph[block.start_ea] = list() start_address = block.start_ea end_address = block.end_ea if first isNone: print("Starting") first = start_address ea = 0 if end_address - start_address <= 5: print("found jmp block") exclusive_nodes.append(start_address) for succ in block.succs(): # is a jmp block, ignore it graph[block.start_ea].append(succ.start_ea) continue flag = 0 tgt = 0 while (end_address - ea) != start_address:
if idc.GetDisasm(end_address - ea).startswith("jnz"): # print(int(idc.GetDisasm(end_address - ea)[-4::],16)) flag = 1 tgt = int(idc.GetDisasm(end_address - ea)[-4::],16) elif idc.GetDisasm(end_address - ea).startswith("jz"): flag = 2 tgt = int(idc.GetDisasm(end_address - ea)[-4::], 16) ea += 1 if flag != 0: jmp_dict[block.start_ea] = (flag,tgt) for succ in block.succs(): graph[block.start_ea].append(succ.start_ea)
print(jmp_dict)
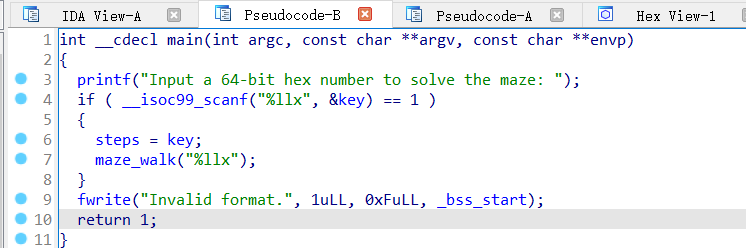
function_address = 0x1500
function = idaapi.get_func(function_address) cfg = idaapi.FlowChart(function)
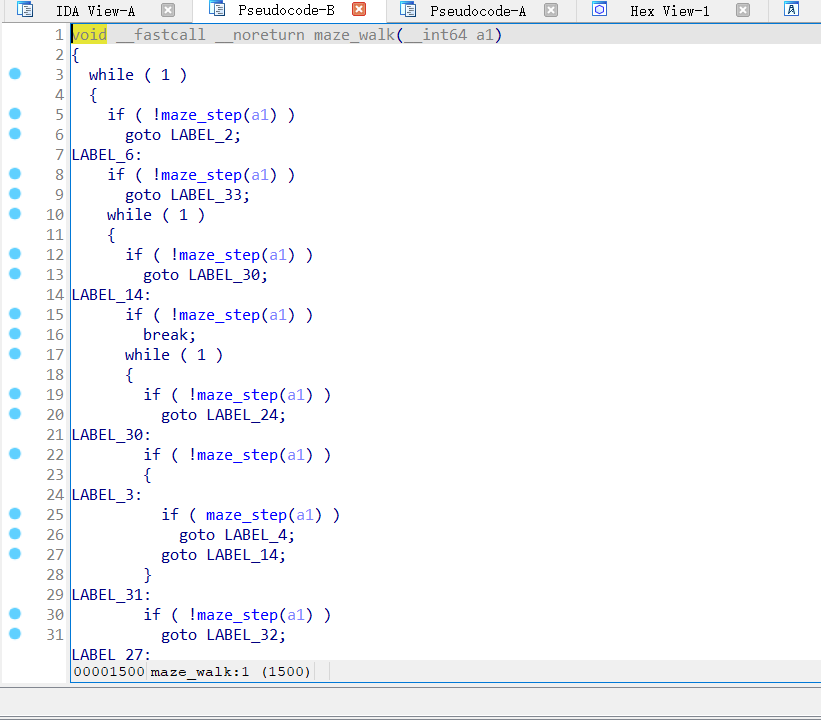
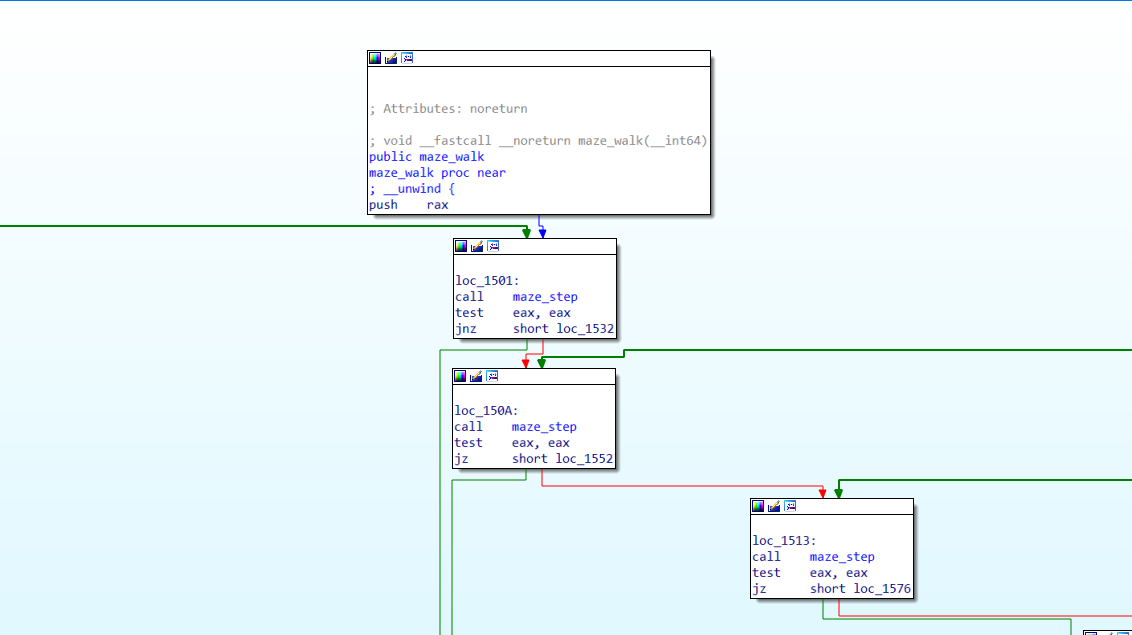
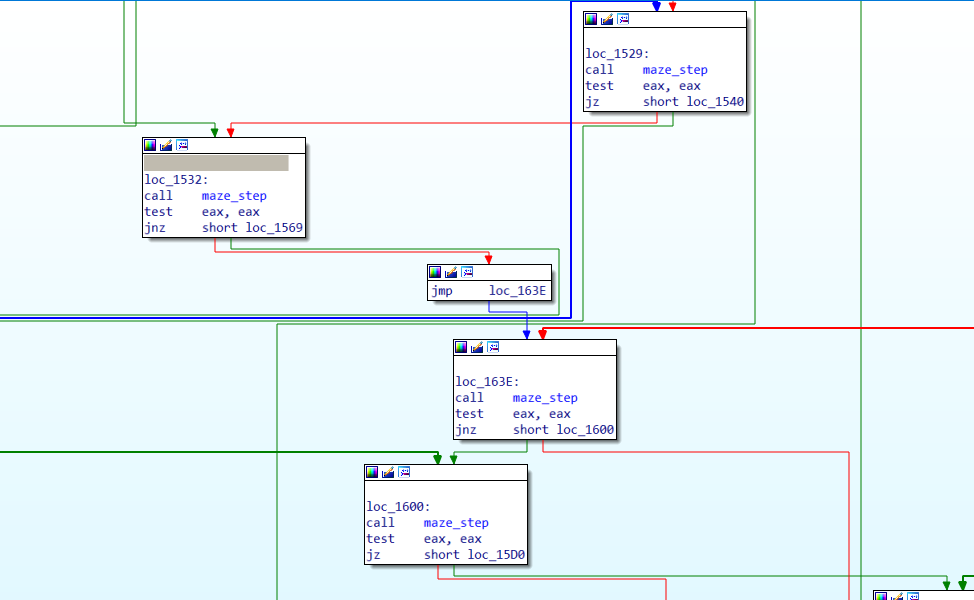
这两句话很简单,得到maze_walk这个函数的对象,并生成函数流程图。
简单来说,就是将IDA中的我们认知的流程图告诉给机器。
graph = dict() exclusive_nodes = list() first = None end = 9177 jmp_dict = dict()
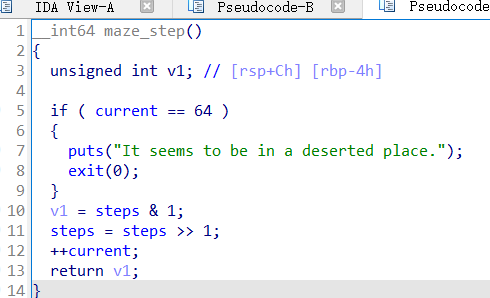
for block in cfg: graph[block.start_ea] = list() #值为一个列表,存储后继节点的开始地址 start_address = block.start_ea end_address = block.end_ea if first isNone: print("Starting") first = start_address #将首节点生成出来 ea = 0# 一个变量,用来遍历这个节点的所有指令,挑选出跳转指令 if end_address - start_address <= 5: #判断当前节点是是jmp块 print("found jmp block") exclusive_nodes.append(start_address) #将jmp块列为排除节点 for succ in block.succs(): # is a jmp block, ignore it graph[block.start_ea].append(succ.start_ea) #将当前jmp块的所有后继节点加入graph continue#下面的是非jmp块应该执行的内容,jmp直接continue flag = 0#判断从当前节点到部分后继节点是如何过去的,jnz还是jz tgt = 0#后继节点的地址 while (end_address - ea) != start_address: #看循环最后有一个ea+=1,ea的作用是用end_address - ea来索引指令
if idc.GetDisasm(end_address - ea).startswith("jnz"):#某个指令是以jnz开头的 # print(int(idc.GetDisasm(end_address - ea)[-4::],16)) flag = 1#标记为1 tgt = int(idc.GetDisasm(end_address - ea)[-4::],16) #记录下后继节点的开始地址 elif idc.GetDisasm(end_address - ea).startswith("jz"):#同上 flag = 2 tgt = int(idc.GetDisasm(end_address - ea)[-4::], 16) ea += 1 if flag != 0: # 当前节点是通过jz或jnz转移到别的节点的 jmp_dict[block.start_ea] = (flag,tgt) #记录一下转移方式与地址 for succ in block.succs(): graph[block.start_ea].append(succ.start_ea) #记录后继节点的开始位置
defBFS(grap, star): # BFS算法 queue = [] # 定义一个队列 seen = set() # 建立一个集合,集合就是用来判断该元素是不是已经出现过 queue.append(star) # 将任一个节点放入 seen.add(star) # 同上 parent = {star: None} # 存放parent元素 while (len(queue) > 0): # 当队列里还有东西时 ver = queue.pop(0) # 取出队头元素 notes = grap[ver] # 查看grep里面的key,对应的邻接点 for q in notes:
if q in seen: #从这开始均为本人修改 continue if q ==9177: parent[q]=ver seen.add(q) continue if q in exclusive_nodes: nex=grap[q][0] if nex in seen: #这句话卡了作者两个小时 continue parent[nex]=q parent[q]=ver seen.add(q) seen.add(nex) queue.append(nex) if q notin exclusive_nodes: parent[q] = ver seen.add(q) queue.append(q) return parent
parent = BFS(graph, first)
p = [] a = end while a != None: p.append(a) a = parent[a] path = p path=path[::-1]
import idc import idaapi startaddr=0x401210 endaddr=0x41DDB2 for i inrange(startaddr,endaddr): a=idc.get_wide_dword(i) if a==0xe5894855: if idaapi.get_func(i): continue else: idaapi.add_func(i) # 批量创建函数
import idc addr=0x12A4+96 startaddr=addr+128*32 endaddr=addr+128*127 cha=chr(32) for i inrange(startaddr,endaddr,128): func_name="func_{0}_{1}".format(ord(cha),cha) idc.set_name(i,func_name,256) print(func_name,hex(i)) cha=chr(ord(cha)+1) #快速给函数重命名
import idc import idaapi startaddr=0x11C9 endaddr=0x15AE lis=[0x50, 0x51, 0x52, 0x53, 0xE8, 0x00, 0x00, 0x00, 0x00, 0x5B, 0x48, 0x81, 0xC3, 0x12, 0x00, 0x00, 0x00, 0x48, 0x89, 0x5C, 0x24, 0x18, 0x48, 0x83, 0xC4, 0x18,0xC3] for i inrange(startaddr,endaddr): flag=True for j inrange(i,i+27): if idc.get_wide_byte(j)!=lis[j-i]: flag=False if flag==True: for addr inrange(i,i+27): idc.patch_byte(addr,0x90) for i inrange(startaddr,endaddr):# 将这段全部取消定义(U) idc.del_items(i) for i inrange(startaddr,endaddr): #如果这条指令时endbr64,就定义函数(P) if idc.get_wide_dword(i)==0xFA1E0FF3: #endbr64 idaapi.add_func(i) # iDA快速去除花指令之后定义函数